Web Scraper¶
Extracts content from one or more web pages and optionally answers queries based on the scraped data. Supports recursive scraping up to a specified depth.
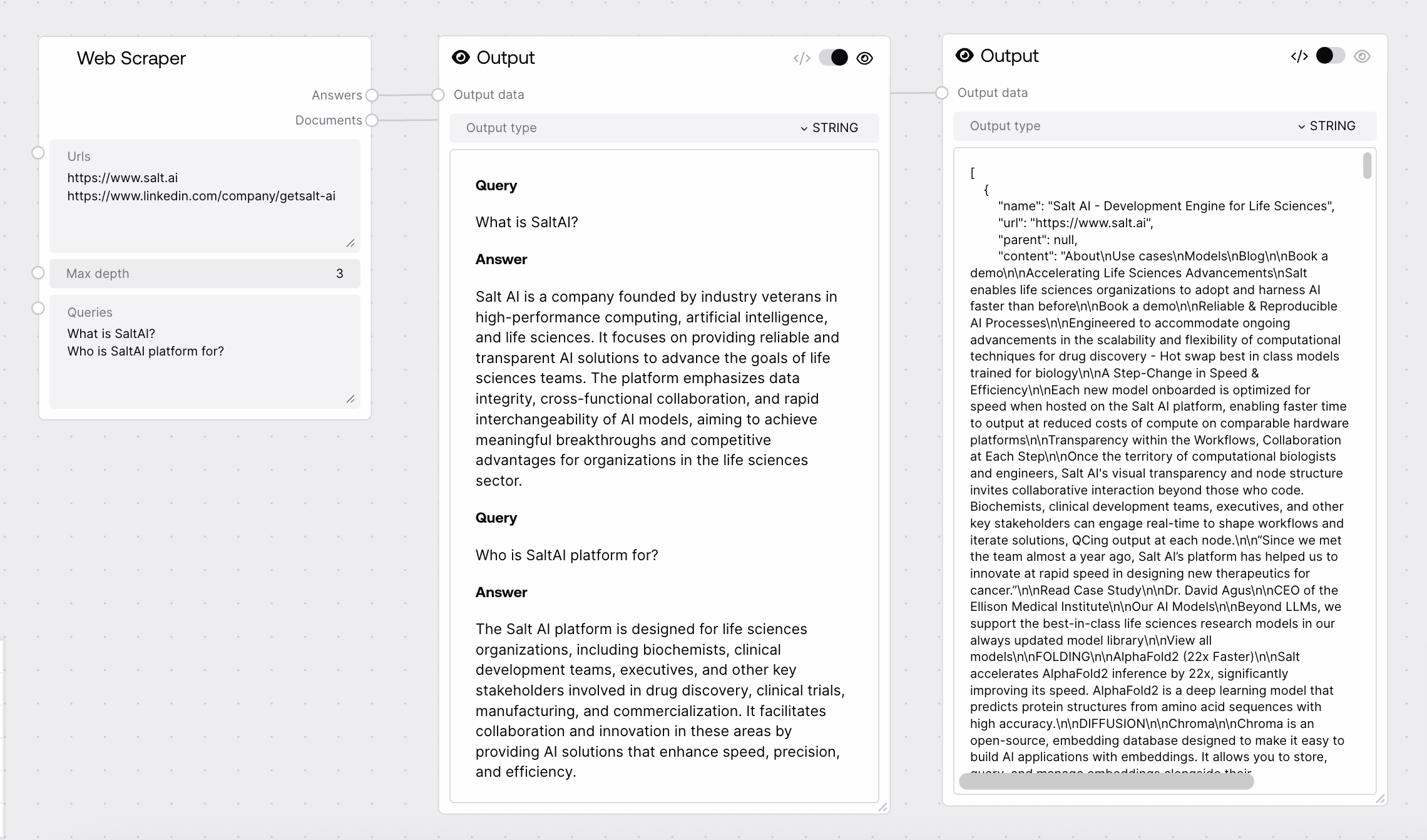
Quick Start¶
- Enter one or more URLs (separated by line breaks).
- Set the desired maximum depth for recursive scraping.
- (Optional) Enter queries to answer using the scraped content.
- Run the node to receive extracted documents and query answers.
Setup Guide¶
1. Provide URLs¶
- List the web pages to scrape, each on a new line.
- Ensure URLs are accessible and valid.
2. Configure Scraping Depth and Queries¶
- Set
max_depthto control recursion (0 = only provided URLs). - Optionally, add queries to extract specific information from the content.
Basic Usage¶
Scrape Single or Multiple Pages¶
- Scrape a single web page for its content.
- Scrape multiple URLs at once by listing them line by line.
Recursive Scraping¶
- Set
max_depth> 0 to follow links and scrape additional pages up to the specified depth.
Querying Scraped Data¶
- Provide questions to extract targeted information from the scraped content.
Configuration¶
Required Inputs¶
| Field | Description | Type | Example |
|---|---|---|---|
| urls | One or more URLs to scrape (separated by line breaks) | STRING | https://example.com |
| max_depth | Maximum recursion depth (0 = only provided URLs) | INT | 1 |
| queries | (Optional) Queries to answer from scraped data | STRING | What is the page title? |
Optional Inputs¶
None
Outputs¶
| Field | Description | Example |
|---|---|---|
| answers | Answers to provided queries (if any) | See below |
| documents | JSON array of scraped documents | See below |
Best Practices¶
Efficient Scraping¶
- Limit
max_depthto avoid excessive requests and timeouts. - Provide only necessary queries to reduce processing time.
Data Quality¶
- Use valid, reachable URLs for best results.
- Review scraped content for completeness and accuracy.
Troubleshooting¶
Common Issues¶
- Timeout error: Reduce the number of URLs or lower
max_depth. - Invalid URL: Ensure all URLs are correctly formatted and accessible.
- Empty answers: Check that queries are relevant to the scraped content.
Need Help?¶
- Review node configuration and input values.
- Check service logs for error details.